Here we’ll take a problem of binary image classifing.
Code
from IPython.display import display, HTML"<style>.container { width:80% !important; }</style>" ))import numpy as npimport torchimport torch.optim as optimimport torch.nn as nnfrom shared.step_by_step import StepByStepimport platformfrom PIL import Imageimport datetimeimport matplotlib.pyplot as pltfrom matplotlib import cmfrom torch.utils.data import DataLoader, Dataset, random_split, WeightedRandomSampler, SubsetRandomSamplerfrom torchvision.transforms import Compose, ToTensor, Normalize, ToPILImage, RandomHorizontalFlip, Resize'fivethirtyeight' )
Code
def show_image(im, cmap= None ):= plt.figure(figsize= (3 ,3 ))= cmap)False )
Data
We’ll use generated data, where images with horizontal and vertical lines are considered label 0, while diagonal have label 1.
Code
def gen_img(start, target, fill= 1 , img_size= 10 ):# Generates empty image = np.zeros((img_size, img_size), dtype= float )= None , None if start > 0 := startelse := np.abs (start)if target == 0 :if start_row is None := fillelse := fillelse :if start_col == 0 := 1 if target == 1 :if start_row is not None := (range (start_row, - 1 , - 1 ), range (0 , start_row + 1 ))else := (range (img_size - 1 , start_col - 1 , - 1 ), range (start_col, img_size))= fillelse :if start_row is not None := (range (start_row, img_size, 1 ), range (0 , img_size - start_row))else := (range (0 , img_size - 1 - start_col + 1 ), range (start_col, img_size))= fillreturn 255 * img.reshape(1 , img_size, img_size)def generate_dataset(img_size= 10 , n_images= 100 , binary= True , seed= 17 ):= np.random.randint(- (img_size - 1 ), img_size, size= (n_images,))= np.random.randint(0 , 3 , size= (n_images,))= np.array([gen_img(s, t, img_size= img_size) for s, t in zip (starts, targets)], dtype= np.uint8)if binary:= (targets > 0 ).astype(int )return images, targetsdef plot_images(images, targets, n_plot= 30 ):= n_plot // 6 + ((n_plot % 6 ) > 0 )= plt.subplots(n_rows, 6 , figsize= (9 , 1.5 * n_rows))= np.atleast_2d(axes)for i, (image, target) in enumerate (zip (images[:n_plot], targets[:n_plot])):= i // 6 , i % 6 = axes[row, col]'# {} - Label: {} ' .format (i, target), {'size' : 12 })# plot filter channel in grayscale = 'gray' , vmin= 0 , vmax= 1 )for ax in axes.flat:return fig
= generate_dataset(img_size= 5 , n_images= 300 , binary= True , seed= 13 )
= plot_images(images, labels, n_plot= 30 )
Data preparation
= torch.as_tensor(images / 255. ).float ()= torch.as_tensor(labels.reshape(- 1 , 1 )).float () # reshaped this to (N,1) tensor
PyTorch has Dataset class, TensorDataset as a subclass, and we can create custom subclasses too that can handle data augmentation :
class TransformedTensorDataset(Dataset):def __init__ (self , x, y, transform= None ):self .x = xself .y = yself .transform = transformdef __getitem__ (self , index):= self .x[index]if self .transform:= self .transform(x)return x, self .y[index]def __len__ (self ):return len (self .x)
A torch.utils.data.random_split method can split indices into train and valid (it requires exact number of images to split):
13 )= len (x_tensor)= int (.8 * N)= N - n_train= random_split(x_tensor, [n_train, n_val])
<torch.utils.data.dataset.Subset>
we just need indices:
= train_subset.indices= val_subset.indices
[118, 170, 148, 239, 226, 146, 168, 195, 6, 180]
Data augmentation
For data augmentation we only augment training data, so we create training and validation Composer :
= Compose([RandomHorizontalFlip(p= .5 ),= (.5 ,), std= (.5 ,))])= Compose([Normalize(mean= (.5 ,), std= (.5 ,))])
Now we can build train/val tensors, Datasets and DataLoaders:
= x_tensor[train_idx]= y_tensor[train_idx]= x_tensor[val_idx]= y_tensor[val_idx]= TransformedTensorDataset(x_train_tensor, y_train_tensor, transform= train_composer)= TransformedTensorDataset(x_val_tensor, y_val_tensor, transform= val_composer)
We could stop here and just make loaders:
# Builds a loader of each set = DataLoader(dataset= train_dataset, batch_size= 16 , shuffle= True )= DataLoader(dataset= val_dataset, batch_size= 16 )
or we can even used WeightedRandomSampler if we want to balance datasets:
def make_balanced_sampler(y):# Computes weights for compensating imbalanced classes = y.unique(return_counts= True )= 1.0 / counts.float ()= weights[y.squeeze().long ()]# Builds sampler with compute weights = torch.Generator()= WeightedRandomSampler(= sample_weights,= len (sample_weights),= generator,= True return sampler
Note that we don’t need a val_sampler anymore since we already split datasets:
= make_balanced_sampler(y_train_tensor)
= DataLoader(dataset= train_dataset, batch_size= 16 , sampler= train_sampler)= DataLoader(dataset= val_dataset, batch_size= 16 )
Logistic Regression Model
= 0.1 # Now we can create a model = nn.Sequential()'flatten' , nn.Flatten())'output' , nn.Linear(25 , 1 , bias= True ))'sigmoid' , nn.Sigmoid())# Defines a SGD optimizer to update the parameters = optim.SGD(model_logistic.parameters(), lr= lr)# Defines a binary cross entropy loss function = nn.BCELoss()
= StepByStep(model_logistic, optimizer_logistic, binary_loss_fn)200 )
Failed to set loader seed.
100%|██████████| 200/200 [00:08<00:00, 23.24it/s]
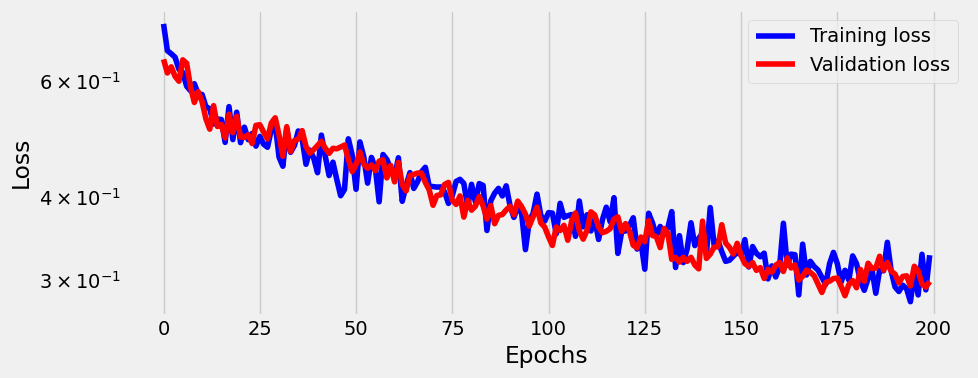
= sbs_logistic.plot_losses()
Code
print ('Correct categories:' )print (sbs_logistic.loader_apply(sbs_logistic.val_loader, sbs_logistic.correct))
Correct categories:
tensor([[24, 24],
[34, 36]])
After 200 epoch it’s almost 100%. Let’s add 400 more:
100%|██████████| 400/400 [00:13<00:00, 29.00it/s]
Code
print ('Correct categories:' )print (sbs_logistic.loader_apply(sbs_logistic.val_loader, sbs_logistic.correct))
Correct categories:
tensor([[24, 24],
[36, 36]])
so after 600 epoch model is 100% accurate (at least on 60 samples).
Deeper Model
= 0.1 # Now we can create a model = nn.Sequential()'flatten' , nn.Flatten())'linear1' , nn.Linear(25 , 10 , bias= True ))'relu' , nn.ReLU())'linear2' , nn.Linear(10 , 1 , bias= True ))'sigmoid' , nn.Sigmoid())# Defines a SGD optimizer to update the parameters = optim.SGD(model_deeper.parameters(), lr= lr)# Defines a binary cross entropy loss function = nn.BCELoss()
= StepByStep(model_deeper, optimizer_deeper, binary_loss_fn)20 )
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [00:00<00:00, 28.33it/s]
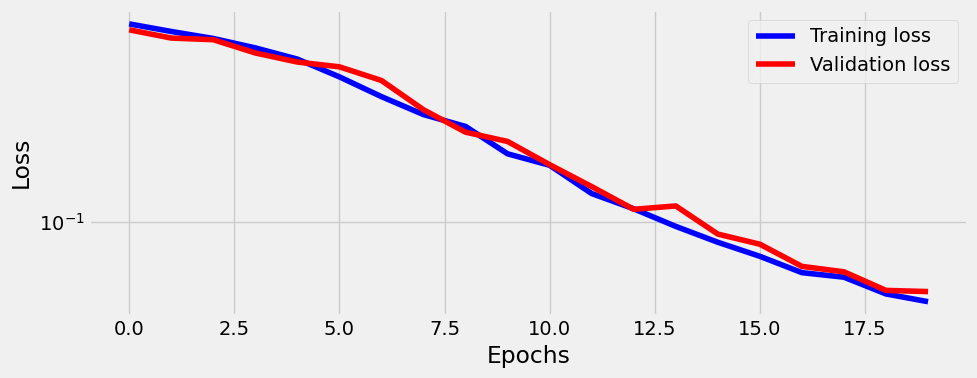
= sbs_deeper.plot_losses()
Code
print ('Correct categories:' )print (sbs_deeper.loader_apply(sbs_deeper.val_loader, sbs_deeper.correct))
Correct categories:
tensor([[24, 24],
[36, 36]])
and even after 20 epoch it’s 100% accurate. We can train more to flatten the loss though which will surely generalize model:
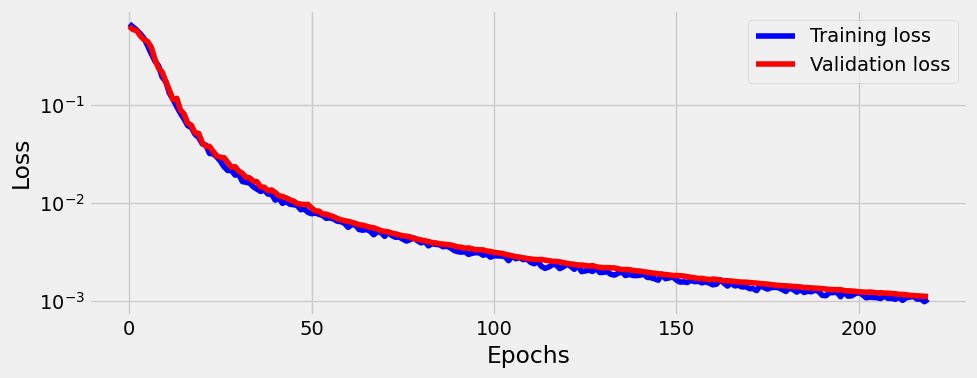
200 )= sbs_deeper.plot_losses()
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:06<00:00, 30.26it/s]
And that’s it.